2023. december 17. 22:51, Vasárnap
A ChatGPT-ről híres cég úgy gondolja, hogy közeleg az emberfeletti MI - és eszközöket akar építeni az irányításához.
A Sam Altman
kirúgása körüli botrány ugyan megtépázta a cég hírnevét, de attól még az OpenAI vezeti az MI-forradalmat,
Superalignment csapatának tagjai pedig szorgalmasan dolgoznak azon a problémán, hogyan lehet az embernél okosabb mesterséges intelligenciát irányítani. A csapat három tagja - Collin Burnst, Pavel Izmailovot és Leopold Aschenbrennert - New Orleansban, a NeurIPS gépi tanulási konferencián tartottak előadást, hogy bemutassák az OpenAI milyen eredményeket ért el annak biztosítása érdekében, hogy a mesterséges intelligencia rendszerek a kívánt módon viselkedjenek. Az OpenAI júliusban hozta létre a Superalignment csapatot, hogy kidolgozza a "szuperintelligens" mesterséges intelligencia rendszerek - vagyis az emberekét messze meghaladó intelligenciával rendelkező, ma még csak elméletileg létező rendszerek - irányításának, szabályozásának és kormányzásának módjait.
"Ma alapvetően olyan modelleket tudunk összehangolni, amelyek butábbak nálunk, vagy legfeljebb az emberi szint körül mozognak" - mondta Burns. "Egy olyan modell összehangolása, amely valóban okosabb nálunk, sokkal, de sokkal kevésbé nyilvánvaló - hogyan tudjuk egyáltalán megcsinálni?" A Superalignment erőfeszítést az OpenAI társalapítója és vezető tudósa, Ilya Sutskever vezeti, ami júliusban még nem keltett feltűnést - de most már bizonyára igen, annak fényében, hogy Sutskever azok között volt, akik Altman kirúgását szorgalmazták. Bár egyes jelentések szerint Sutskever Altman visszatérését követően "bizonytalan helyzetben" van, az OpenAI PR-osztálya szerint Sutskever valóban - legalábbis a mai napig - még mindig a Superalignment csapat élén áll.

Sam Altman és Ilya Sutskever
A Superalignment egy kicsit kényes téma az MI kutatói közösségen belül. Egyesek szerint az alterület még korai, mások szerint pedig csak egy elterelő hadművelet. Míg Altman szerint az OpenAI hatása az atombomba létrehozását célzó Manhattan Projecthez mérhető, addig más szakértők szerint kevés bizonyíték van arra, hogy a startup technológiája hamarosan - vagy valaha is - világmegváltó, az embereket felülmúló képességekre tesz szert. E szakértők hozzáteszik, hogy a közelgő szuperintelligenciára vonatkozó állítások csak arra szolgálnak, hogy szándékosan eltereljék a figyelmet napjaink égető szabályozási kérdéseiről, például az algoritmikus elfogultságról és az MI toxicitásra való hajlamáról.
Sutskever úgy tűnik, komolyan hisz abban, hogy a mesterséges intelligencia - nem az OpenAI önmagában, hanem annak valamilyen megtestesülése - egy nap egzisztenciális fenyegetést jelenthet. Állítólag az OpenAI számítási kapacitásának jelentős részét - a meglévő számítógépes chipek 20%-át - a Superalignment csapat kutatásaihoz rendelte. "Az MI fejlődése az utóbbi időben rendkívül gyors volt, és biztosíthatom önöket, hogy nem lassul" - mondta Aschenbrenner. "Szerintem hamarosan elérjük az emberi szintű rendszereket, de nem állunk meg itt - egészen az emberfeletti rendszerekig fogunk eljutni. Hogyan hangoljuk össze a szuperemberi mesterséges intelligencia rendszereket, és hogyan tegyük őket biztonságossá? Ez tényleg az egész emberiség problémája - talán korunk legfontosabb megoldatlan műszaki problémája."
A Superalignment csapat jelenleg olyan irányítási és ellenőrzési keretrendszerek kiépítésén fáradozik, amelyek jól alkalmazhatók lehetnek a jövő nagy teljesítményű MI-rendszereihez. Ez nem egyszerű feladat, tekintve, hogy a "szuperintelligencia" definíciója - és az, hogy egy adott mesterséges intelligencia rendszer elérte-e azt - erőteljes vita tárgya. De a csapat egyelőre arra a megközelítésre jutott, hogy egy gyengébb, kevésbé kifinomult AI-modellt (pl. GPT-2) arra használnak, hogy egy fejlettebb, kifinomultabb modellt (GPT-4) a kívánatos irányokba tereljenek - és távol tartsanak a nem kívánatosaktól.
"Sok mindent megpróbálunk megtenni, hogy megmondjuk egy modellnek, mit kell tennie, és biztosítjuk, hogy az meg is tegye" - mondta Burns. "Hogyan érjük el, hogy egy modell kövesse az utasításokat, és hogyan érjük el, hogy egy modell csak olyan dolgokban segítsen, amelyek igazak, és ne találjon ki dolgokat? Hogyan érjük el, hogy egy modell megmondja, hogy az általa generált kód biztonságos vagy egzaltált viselkedés? Ilyen típusú feladatokat szeretnénk elérni a kutatásunkkal".
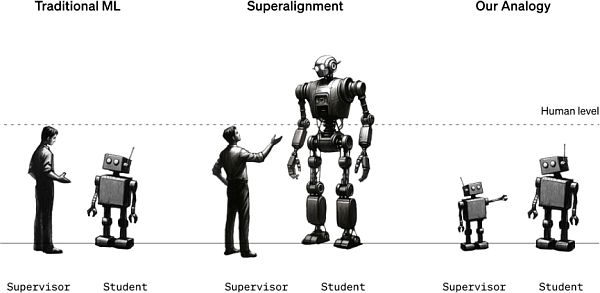
A jelenlegi ötlet szerint egy ember által megérthető modell fogja felügyelni az emberit meghaladó intelligenciát
De várjunk csak, mondhatnánk - mi köze van a mesterséges intelligenciát irányító mesterséges intelligenciának az emberiséget fenyegető mesterséges intelligencia megelőzéséhez? Nos, ez egy analógia: a gyenge modell az emberi felügyelőket hivatott helyettesíteni, míg az erős modell a szuperintelligens MI-t képviseli. Hasonlóan az emberekhez, akik esetleg nem lennének képesek értelmet adni egy szuperintelligens MI-rendszernek, a gyenge modell nem tudja "megérteni" az erős modell minden komplexitását és árnyalatát - így a felállás hasznos a szuperintelligens hipotézisek bizonyítására, mondja a Superalignment csapata. "Gondoljunk egy hatodik osztályos diákra, aki megpróbál felügyelni egy főiskolás diákot" - magyarázta Izmailov. "Tegyük fel, hogy a hatodik osztályos megpróbál elmondani a főiskolásnak egy olyan feladatot, amelyet ő nem tud megoldani. Még ha a hatodik osztályos által adott felügyeletnek lehetnek is hibái a részletekben, van remény arra, hogy a főiskolás megérti a lényeget, és jobban meg tudja oldani a feladatot, mint a felügyelő."
A Superalignment csapatnál egy adott feladatra finomhangolt gyenge modell címkéket generál, amelyek segítségével az adott feladat nagy vonalakban "kommunikálható" az erős modell felé. E címkék ismeretében az erős modell a gyenge modell szándékának megfelelően többé-kevésbé helyesen tud általánosítani - még akkor is, ha a gyenge modell címkéi hibákat és torzításokat tartalmaznak, állapította meg a csapat.
A gyenge-erős modell megközelítés akár a
hallucinációk területén is áttörést hozhat. "A hallucinációk valójában elég érdekesek, mert belsőleg a modell valójában tudja, hogy amit mond, az tény vagy kitaláció" - mondta Aschenbrenner. "De ezeket a modelleket manapság úgy képzik, hogy az emberi felügyelők "hüvelykujj felfelé", "hüvelykujj lefelé" jelekkel jutalmazzák őket, ha mondanak valamit. Így néha az emberek akaratlanul is jutalmazzák a modellt olyan dolgokért, amelyek vagy hamisak, vagy amelyekről a modell valójában nem is tud, és így tovább. Ha sikeresek leszünk a kutatásainkban, olyan technikákat kellene kifejlesztenünk, amelyekkel alapvetően megidézhetjük a modell tudását, és ezt a megidézést alkalmazhatnánk arra vonatkozóan, hogy valami tény vagy fikció. Ezt felhasználhatnánk a hallucinációk csökkentésére".
Az OpenAI mégsem elégedett, ezért nyilvánosan akarnak ötleteket gyűjteni. Ebből a célból a cég egy 10 millió dolláros támogatási programot indít a Superalignment kérdéssel kapcsolatos technikai kutatások támogatására, amelynek részleteit egyetemi laboratóriumok, nonprofit szervezetek, egyéni kutatók és végzős hallgatók számára tartják fenn. Az OpenAI azt is tervezi, hogy 2025 elején egy tudományos konferenciát is rendez a témában, ahol megosztják és népszerűsítik a díj döntőseinek munkáját.
Érdekes módon a támogatás finanszírozásának egy része a Google korábbi vezérigazgatójától és elnökétől, Eric Schmidttől származik. Schmidt - aki lelkes támogatója Altmannak - hamar a mesterséges intelligenciával kapcsolatos végítélet jóslások élére állt, azt állítva, hogy közeleg a veszélyes mesterséges intelligencia rendszerek megérkezése és hogy a szabályozó hatóságok nem tesznek eleget a felkészülés érdekében. Ez nem feltétlenül önzetlenségből fakad: Schmidt aktív MI befektetőként kereskedelmi szempontból óriási hasznot húzhatna abból, ha az amerikai kormány végrehajtaná az általa javasolt tervezetet az MI-kutatás támogatására.
Az adományozás tehát cinikus szemszögből nézve irányjelzésnek is felfogható. Schmidt személyes vagyona a becslések szerint 24 milliárd dollár körül mozog, és több százmilliót ölt más, kifejezetten
kevésbé etikus MI-vállalkozásokba és -alapokba - beleértve a sajátját is. Schmidt persze tagadja, hogy ez így lenne. "A mesterséges intelligencia és más feltörekvő technológiák átalakítják gazdaságunkat és társadalmunkat" - írja nyilatkozatában. "Az emberi értékekkel való összehangolásuk biztosítása kritikus fontosságú, és büszkén támogatom az OpenAI új programjait, hogy a közjó érdekében felelősségteljesen fejlesszük és ellenőrizzük az MI-t."
Az OpenAI azt ígéri, hogy a Superalignment kutatásai, valamint a közösség jövőbeli konferenciáján szereplő ötletei bárki számára elérhetővé válnak, hogy azt saját belátása szerint felhasználhassa. "Nemcsak a mi modelljeink biztonságához, hanem más laboratóriumok modelljeinek és általában a fejlett mesterséges intelligenciának a biztonságához való hozzájárulás a küldetésünk része" - mondta Aschenbrenner. "A küldetésünk lényege, hogy az egész emberiség javát szolgáló MI-t építsünk, biztonságosan. És úgy gondoljuk, hogy ez a kutatás elengedhetetlenül fontos ahhoz, hogy hasznos és biztonságos legyen".