SG.hu·
A francia Mistral Európa aduja az MI versenyben

A Mistral a hét elején jelentette be Mixtral 8x7B nevű új MI nyelvi modelljét, egy szabadon letölthető keverékmodellt (mixture of experts, MoE), amely állítólag felveszi a versenyt az OpenAI GPT-3.5 tudásával. Ilyet korábban mások is állítottak, de a franciák szakértelmét az ágazat olyan nagyágyúi, mint az OpenAI-s Andrej Karpathy és Jim Fan is komolyan veszik. Fejlesztésükkel közelebb kerültünk egy olyan ChatGPT-3.5 szintű MI-asszisztenshez, amely a megfelelő implementáció mellett szabadon és helyben futhat az eszközeinken.
A párizsi székhelyű Mistralt májusban alapította Arthur Mensch, Guillaume Lample és Timothée Lacroix a Google DeepMind és Meta öregdiákjai társaságában. Egy gyorsan növekvő startupról van szó, amely fél év alatt rengeteg kockázati tőkét tudott bevonzani, hogy egyfajta francia anti-OpenAI-vá váljon, és a kisebb, szemet gyönyörködtető teljesítményű modellek bajnoka legyen. A legutóbbi, múlt heti finanszírozási körben 385 millió eurót vont be a társaság, ami nagyjából 2 milliárd dollárra értékeli a céget. A cég fontos szerepet játszott az EU mesterséges intelligenciáról szóló törvénye körüli viták alakításában: a francia MI-startup az alapmodellek teljes mentesítéséért lobbizott, mondván, hogy a szabályozásnak a felhasználási esetekre és az olyan termékeken dolgozó vállalatokra kell vonatkoznia, amelyeket közvetlenül a végfelhasználók használnak.
Első modelljüket szeptemberben adták ki Mistral 7B néven, de azt még nem a GPT-4 vagy a Claude 2 közvetlen konkurenciájának szánták, csak egy "kis", körülbelül 7 milliárd paramétert tartalmazó adathalmazon képezték ki. Ahelyett, hogy API-kon keresztül nyitottak volna hozzáférést a Mistral 7B modellhez, a vállalat ingyenes letöltésként tette azt elérhetővé, hogy a fejlesztők futtathassák eszközeiken és szervereiken. Bár a modellt bárki futtathatja, azt zárt ajtók mögött fejlesztették ki egy saját tulajdonú és nem nyilvános adathalmazzal. A cég egyes modelljei nyíltak és képesek lokálisan futni, ezek szabadon letölthetők és kevesebb korlátozással használhatók, mint az OpenAI, az Anthropic vagy a Google zárt MI-modellei.
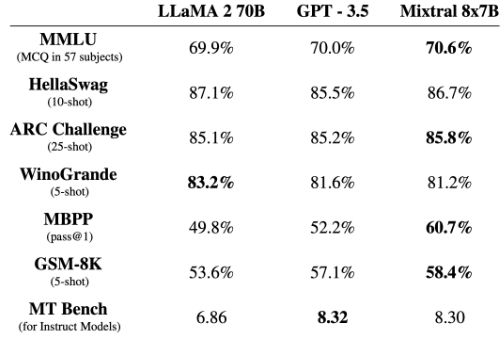
A Mixtral a legtöbb összehasonlító tesztben megegyezik a Llama 2 70B és a GPT3.5 modellel, vagy felülmúlja azokat
A Mixtral 8x7B 32K token méretű kontextusablakot képes feldolgozni, és francia, német, spanyol, olasz és angol nyelven ért. A ChatGPT-hez hasonlóan működik, segíthet adatok elemzésében, szoftverek hibaelhárításában és programok írásában. A Mistral azt állítja, hogy felülmúlja a Meta jóval nagyobb, LLaMA 2 70B (70 milliárd paraméteres) nagy nyelvi modelljét, és bizonyos benchmarkokban megegyezik vagy meghaladja az OpenAI GPT-3.5 modelljével. Sokakat meglepett az a sebesség, amellyel a nyílt mesterséges intelligencia modellek felzárkóztak az OpenAI egy évvel ezelőtti legjobb ajánlatához. Pietro Schirano, az EverArt alapítója azt írta az X-en: "Egyszerűen hihetetlen. A Mistral 8x7B-t 27 token per másodperc sebességgel futtatom, teljesen helyben, hála a @LMStudioAI-nak. Egy olyan modell, amely jobb eredményt ér el, mint a GPT-3.5, lokálisan. Képzeld el, hol leszünk 1 év múlva."
A LexicaArt alapítója, Sharif Shameem szerint a Mixtral MoE modell valóban áttörésnek tűnik, "egy igazi GPT-3.5 szintű modell, amely 30 token/sec sebességgel fut egy Apple M1-en." Andrej Karpathy szerint "a következtetési teljesítmény nagyot lépett előre, a lemaradás inkább a felhasználói felület terén van."
A MoE modell szabad fordításban "szakértők keverékét" jelenti, egy olyan gépi tanulási modellarchitektúrára utal, ahol egy kapuból a bemeneti adatok különböző specializált neurális hálózati komponensekhez, úgynevezett "szakértőkhöz" kerülnek feldolgozásra. Ennek előnye, hogy hatékonyabb és skálázhatóbb modellképzést és következtetést tesz lehetővé, mivel minden bemenetre csak a szakértők egy részhalmaza aktiválódik, csökkentve a számítási terhelést az azonos paraméterszámú monolitikus modellekhez képest. "Ez a technika növeli a modell paramétereinek számát, miközben kontrollálja a költségeket és a késleltetést, mivel a modell a teljes paraméterkészletnek csak egy töredékét használja tokenenként. Konkrétan a Mixtralnak 45B összes paramétere van, de tokenenként csak 12B paramétert használ. Ezért ugyanolyan sebességgel és költséggel dolgozza fel a bemenetet és generálja a kimenetet, mint egy 12B modell" - írta a vállalat egy blogbejegyzésben.
Laikusan fogalmazva, a MoE olyan, mintha egy gyárban lenne egy csapat speciális munkás (a "szakértők"), ahol egy intelligens rendszer (a "kapu") dönti el, hogy melyik munkás a legalkalmasabb az egyes konkrét feladatok elvégzésére. Ez a felállás hatékonyabbá és gyorsabbá teszi az egész folyamatot, mivel minden feladatot az adott terület szakértője végez el, és nem kell minden munkásnak minden feladatban részt vennie, ellentétben egy hagyományos gyárral, ahol minden munkásnak mindenből egy kicsit mindent el kell végeznie.
Az OpenAI a pletykák szerint MoE rendszert használ a GPT-4-nél, a teljesítményének egy részéért ez felelős. A Mixtral 8x7B esetében a név azt sugallja, hogy a modell nyolc darab 7 milliárd paraméteres neurális hálózat keveréke, de ahogy Karpathy egy tweetben rámutatott, a név kissé félrevezető, mert "nem az összes 7 milliárd paramétert nyolcszorozzák, csak egyes blokkokat. Ezért is van az, hogy a paraméterek teljes száma nem 56, hanem csak 46,7 milliárd."
A Mixtral nem az első nyílt szakértői keverék modell, de figyelemre méltó viszonylag kis mérete a paraméterek számát és az így elért teljesítményt tekintve. Megjelent, szabadon elérhető az Apache 2.0 licenc alatt. Ez a nyílt forráskódú licenc a felhasználásra vagy a sokszorosításra vonatkozóan a tulajdonosi hozzájáruláson kívül semmilyen korlátozást nem tartalmaz. Az emberek helyben futtathatják az LM Studio nevű alkalmazással, de a Mistral béta hozzáférést kínál modelljei három magasabb szintjéhez is. Ezek már csak API-n keresztül érhetők el, mert a vállalat azt tervezi, hogy pénzt keres az alapmodellekből.
A párizsi székhelyű Mistralt májusban alapította Arthur Mensch, Guillaume Lample és Timothée Lacroix a Google DeepMind és Meta öregdiákjai társaságában. Egy gyorsan növekvő startupról van szó, amely fél év alatt rengeteg kockázati tőkét tudott bevonzani, hogy egyfajta francia anti-OpenAI-vá váljon, és a kisebb, szemet gyönyörködtető teljesítményű modellek bajnoka legyen. A legutóbbi, múlt heti finanszírozási körben 385 millió eurót vont be a társaság, ami nagyjából 2 milliárd dollárra értékeli a céget. A cég fontos szerepet játszott az EU mesterséges intelligenciáról szóló törvénye körüli viták alakításában: a francia MI-startup az alapmodellek teljes mentesítéséért lobbizott, mondván, hogy a szabályozásnak a felhasználási esetekre és az olyan termékeken dolgozó vállalatokra kell vonatkoznia, amelyeket közvetlenül a végfelhasználók használnak.
Első modelljüket szeptemberben adták ki Mistral 7B néven, de azt még nem a GPT-4 vagy a Claude 2 közvetlen konkurenciájának szánták, csak egy "kis", körülbelül 7 milliárd paramétert tartalmazó adathalmazon képezték ki. Ahelyett, hogy API-kon keresztül nyitottak volna hozzáférést a Mistral 7B modellhez, a vállalat ingyenes letöltésként tette azt elérhetővé, hogy a fejlesztők futtathassák eszközeiken és szervereiken. Bár a modellt bárki futtathatja, azt zárt ajtók mögött fejlesztették ki egy saját tulajdonú és nem nyilvános adathalmazzal. A cég egyes modelljei nyíltak és képesek lokálisan futni, ezek szabadon letölthetők és kevesebb korlátozással használhatók, mint az OpenAI, az Anthropic vagy a Google zárt MI-modellei.
A Mixtral a legtöbb összehasonlító tesztben megegyezik a Llama 2 70B és a GPT3.5 modellel, vagy felülmúlja azokat
A Mixtral 8x7B 32K token méretű kontextusablakot képes feldolgozni, és francia, német, spanyol, olasz és angol nyelven ért. A ChatGPT-hez hasonlóan működik, segíthet adatok elemzésében, szoftverek hibaelhárításában és programok írásában. A Mistral azt állítja, hogy felülmúlja a Meta jóval nagyobb, LLaMA 2 70B (70 milliárd paraméteres) nagy nyelvi modelljét, és bizonyos benchmarkokban megegyezik vagy meghaladja az OpenAI GPT-3.5 modelljével. Sokakat meglepett az a sebesség, amellyel a nyílt mesterséges intelligencia modellek felzárkóztak az OpenAI egy évvel ezelőtti legjobb ajánlatához. Pietro Schirano, az EverArt alapítója azt írta az X-en: "Egyszerűen hihetetlen. A Mistral 8x7B-t 27 token per másodperc sebességgel futtatom, teljesen helyben, hála a @LMStudioAI-nak. Egy olyan modell, amely jobb eredményt ér el, mint a GPT-3.5, lokálisan. Képzeld el, hol leszünk 1 év múlva."
Just incredible. I am running Mistral 8x7B instruct at 27 tokens per second, completely locally thanks to @LMStudioAI.
— Pietro Schirano (@skirano) December 11, 2023
A model that scores better than GPT-3.5, locally.
Imagine where we will be 1 year from now. pic.twitter.com/BsHBideReC
A LexicaArt alapítója, Sharif Shameem szerint a Mixtral MoE modell valóban áttörésnek tűnik, "egy igazi GPT-3.5 szintű modell, amely 30 token/sec sebességgel fut egy Apple M1-en." Andrej Karpathy szerint "a következtetési teljesítmény nagyot lépett előre, a lemaradás inkább a felhasználói felület terén van."
A MoE modell szabad fordításban "szakértők keverékét" jelenti, egy olyan gépi tanulási modellarchitektúrára utal, ahol egy kapuból a bemeneti adatok különböző specializált neurális hálózati komponensekhez, úgynevezett "szakértőkhöz" kerülnek feldolgozásra. Ennek előnye, hogy hatékonyabb és skálázhatóbb modellképzést és következtetést tesz lehetővé, mivel minden bemenetre csak a szakértők egy részhalmaza aktiválódik, csökkentve a számítási terhelést az azonos paraméterszámú monolitikus modellekhez képest. "Ez a technika növeli a modell paramétereinek számát, miközben kontrollálja a költségeket és a késleltetést, mivel a modell a teljes paraméterkészletnek csak egy töredékét használja tokenenként. Konkrétan a Mixtralnak 45B összes paramétere van, de tokenenként csak 12B paramétert használ. Ezért ugyanolyan sebességgel és költséggel dolgozza fel a bemenetet és generálja a kimenetet, mint egy 12B modell" - írta a vállalat egy blogbejegyzésben.
Laikusan fogalmazva, a MoE olyan, mintha egy gyárban lenne egy csapat speciális munkás (a "szakértők"), ahol egy intelligens rendszer (a "kapu") dönti el, hogy melyik munkás a legalkalmasabb az egyes konkrét feladatok elvégzésére. Ez a felállás hatékonyabbá és gyorsabbá teszi az egész folyamatot, mivel minden feladatot az adott terület szakértője végez el, és nem kell minden munkásnak minden feladatban részt vennie, ellentétben egy hagyományos gyárral, ahol minden munkásnak mindenből egy kicsit mindent el kell végeznie.
Az OpenAI a pletykák szerint MoE rendszert használ a GPT-4-nél, a teljesítményének egy részéért ez felelős. A Mixtral 8x7B esetében a név azt sugallja, hogy a modell nyolc darab 7 milliárd paraméteres neurális hálózat keveréke, de ahogy Karpathy egy tweetben rámutatott, a név kissé félrevezető, mert "nem az összes 7 milliárd paramétert nyolcszorozzák, csak egyes blokkokat. Ezért is van az, hogy a paraméterek teljes száma nem 56, hanem csak 46,7 milliárd."
A Mixtral nem az első nyílt szakértői keverék modell, de figyelemre méltó viszonylag kis mérete a paraméterek számát és az így elért teljesítményt tekintve. Megjelent, szabadon elérhető az Apache 2.0 licenc alatt. Ez a nyílt forráskódú licenc a felhasználásra vagy a sokszorosításra vonatkozóan a tulajdonosi hozzájáruláson kívül semmilyen korlátozást nem tartalmaz. Az emberek helyben futtathatják az LM Studio nevű alkalmazással, de a Mistral béta hozzáférést kínál modelljei három magasabb szintjéhez is. Ezek már csak API-n keresztül érhetők el, mert a vállalat azt tervezi, hogy pénzt keres az alapmodellekből.