2023. július 6. 09:34, Csütörtök
A generatív MI modellek megváltoztatják a web gazdaságát, és olcsóbbá teszik a gyenge minőségű tartalmak előállítását. Még csak most kezdjük látni ezeknek a változásoknak a hatásait.
Az elmúlt hónapokban egyre több az arra mutató jel, hogy a mesterséges intelligencia lassan átveszi az uralmat a web felett. A Google a keresésnél
linkek helyett válaszokat ad, a ChatGPT-t egész spamoldalak létrehozására
használják, a chatbotok pedig már egymást idézik. A LinkedIn mesterséges intelligenciát
használ a felhasználók ösztönzésére, a Snapchat és az Instagram azt reméli, hogy a botok akkor is
beszélgetnek veled, amikor a barátaid nem. A Reddit moderátorai
bezárták a kaput, a Twitter és az Internet Archive az adatbázisát letöltő botok ellen
küzd, de a
legnagyobb áldozat ezen a téren a Wikipédia. A web a honlapokról forgalmat elterelő alkalmazások és az egyre rövidebb ideig tartó figyelmet jutalmazó algoritmusok miatt eddig sem volt jó állapotban, de a mesterséges intelligencia még nagyobb problémákat okoz.
A probléma rendkívül nagy vonalakban a következő. A '90-es években a világháló olyan hely volt, ahol egyének készítettek dolgokat. Honlapokat, fórumokat és levelezőlistákat csináltak, és egy kis pénzt is kerestek vele. Aztán a vállalatok úgy döntöttek, hogy ők jobban tudják ezt, 2000 után létrejöttek a funkciókban gazdag platformok, amelyekhez bárki csatlakozhatott. Az emberek létrehozták a tartalmakat, megtöltötték azokat szöveggel és képekkel, és más emberek megnézték ezeket. A cégek legfőbb célja a növekedés volt, mert ha egyszer elég ember gyűlik össze valahol, általában van rá mód, hogy pénzt keressenek rajtuk. De a mesterséges intelligencia megváltoztatja ezt a felállást.
Pénz és számítási kapacitás esetén a mesterséges intelligencia rendszerek - különösen a jelenleg divatos generatív modellek - könnyedén skálázódnak. Rengeteg szöveget és képet állítanak elő, és hamarosan zenét és videót is. Kibocsátásuk potenciálisan túlszárnyalhatja azokat a platformokat, amelyekre a hírek, információk és szórakozás terén támaszkodunk. De ezeknek a rendszereknek a minősége gyakran gyenge, és úgy épülnek fel, hogy a mai webet parazita módon használják. Ezeket a modelleket a legutóbbi webes korszakban lefektetett adatrétegeken tréningezték, és az új anyagokat tökéletlenül hozzák létre. A vállalatok a nyílt webről töltik le az információkat, és gépi úton generált tartalommá finomítják azokat, amelyek előállítása olcsó, de kevéssé megbízható. Ez a termék aztán versenyez a figyelemért a korábban létrehozott platformokkal és emberekkel. A webhelyek és a felhasználók jelenleg próbálják eldönteni, hogyan alkalmazkodjanak ezekhez a változásokhoz, vagy hogy egyáltalán képesek-e alkalmazkodni.
A Reddit moderátorai lezárták a fórumaikat, miután a vállalat közölte, hogy meredeken megemeli a külső alkalmazásokkal való hozzáférés díjait. A vállalat vezetői a változtatások okát (részben) az MI-cégek letöltéseivel magyarázták. "A Reddit adathalmaza nagyon értékes" - indokolta a lépést Steve Huffman, a Reddit alapítója és vezérigazgatója. "De nem kell ezt az értéket ingyen odaadnunk a világ legnagyobb cégeinek". Nem ez az egyetlen ok, sokkal inkább az idénre tervezett tőzsdei bevezetés, ami előtt megpróbálják minél jobban feltornászni a fórumrendszer bevételeit. Musk is erre hivatkozott pár napja, amikor korlátozta a Twitteren elolvasható hozzászólások számát. Egyértelmű, hogy a vállalatok újragondolják platformjaik nyitottságát, ami fenyegetést jelent a jelenlegi webre nézve.
A Wikipédia jól ismeri az ilyen lopást. A vállalat információit a Google már régóta felhasználja "tudáspanelek" összeállításához, és az utóbbi években a keresőóriás
fizetni is kezdett ezekért az információkért. A Wikipédia moderátorai azonban
arról vitatkoznak, hogyan használhatnák az újonnan létrejött MI-nyelvi modelleket cikkek létrehozására. Nagyon is tisztában vannak az ezekkel a rendszerekkel kapcsolatos problémákkal, hiszen ezek megtévesztő gördülékenységgel gyártanak tényeket és forrásokat, de a másik serpenyőben ott vannak az egyértelmű előnyök a sebesség és a terjedelem tekintetében. "A Wikipedia számára kockázat a minőség csökkenése, ha olyan dolgok kerülnek be, amelyeket nem ellenőriztek" -
mondta a Motherboardnak Amy Bruckman, az online közösségek professzora és a Should You Believe Wikipedia? című könyv szerzője. "Nem hiszem, hogy baj lenne az első vázlatként történő használattal, de minden pontot ellenőrizni kell" .
A Stack Overflow hasonló, de talán még szélsőségesebb példa. A Wikipedia szerkesztőihez hasonlóan ők is aggódnak a gépek által generált tartalmak minősége miatt. Amikor a ChatGPT tavaly elindult, a Stack Overflow volt az első nagy platform, amely
betiltotta a használatát, mert a moderátorai szerint "bár a ChatGPT által előállított válaszok nagy arányban helytelenek, jellemzően úgy néznek ki, mintha jók lennének". Nagyon könnyű vele válaszokat előállítani, viszont rengeteg időt vesz igénybe az eredmények rendezése, ezért a modok úgy döntöttek, hogy egyszerűen betiltják.
Az oldal vezetőségének azonban más tervei voltak. A vállalat megvétózta ezt, bejelentette, hogy ehelyett használni akarja ezt a technológiát. A Reddithez hasonlóan a Stack Overflow is azt tervezi, hogy
díjat számít fel az adatait letöltő cégeknek és ők maguk is
létrehoznak ilyen eszközt. A moderátorok náluk is sztrájkba kezdtek, itt a vita az oldal szabványairól szól, és hogy ki szerez érvényt nekik. A moderátorok szerint a mesterséges intelligencia kimenete nem megbízható, de a vezetők szerint megéri a kockázatot.
Mindezek a nehézségek azonban elhalványulnak a Google-nál zajló változások mellett. A Google kereső a modern web gazdaságának alapját képezi, az internet nagy részének figyelmét és bevételeit irányítja. A Google-t a Bing MI és a ChatGPT, mint alternatív keresőmotorok népszerűsége sarkallta cselekvésre, és az első oldalon lévő 10 kék linket MI által generált összefoglalókkal akarja helyettesíteni. Ha a vállalat véghezviszi ezt a tervet, akkor a változások földrengésszerűek lesznek.
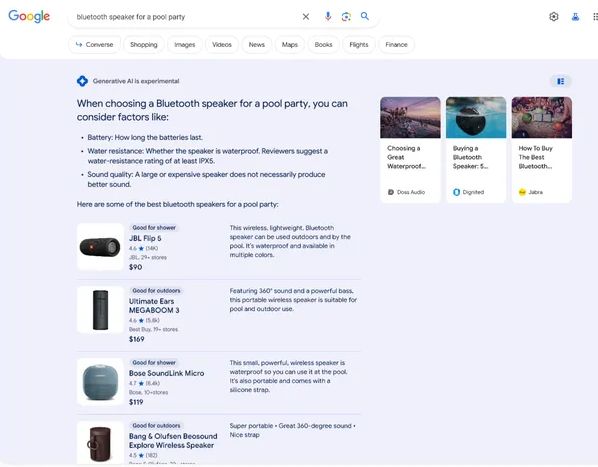
A Google kereső MI-je a források elé helyezi a választ
Avram Piltch, a Tom's Hardware techoldal főszerkesztőjének
írása szerint a Google új rendszere lényegében egy "plágiummotor". Az MI által generált összefoglalók gyakran szóról szóra másolnak szöveget weboldalakról, de ezt a tartalmat a forráslinkek fölé helyezik, ezzel megfosztva azokat a forgalomtól. Ezt a változtatást a Google már régóta tervezte, és a mérleg nyelve határozottan a kivonatolt tartalmak javára tolódott el. Ha a keresésnek ez az új modellje válik általánossá, az az egész webet károsíthatja, hiszen a bevételektől megfosztott oldalak idővel megszűnnek, így maga a Google is kifogy az újracsomagolandó, ember által generált tartalmakból.
A változást az MI alapvető természete hajtja előre, ami a tartalom olcsón való előállítása mások munkája alapján. Nehéz azt megjósolni, mi lesz ha a Google MI-je válaszol minden keresésre. Lehetséges, hogy ez a webet alapjaiban károsítaná, a termékértékelésektől kezdve a receptblogokon, a hobbista honlapokon, a hírportálokon és a wikiken át. A weboldalak védekezhetnének bezárkózással és a hozzáférésért fizetendő díjakkal, de ez a web hatalmas átrendeződését is jelentené. Végül a Google talán megöli az ökoszisztémát, amely értéket teremtett, vagy olyan visszavonhatatlanul megváltoztatja azt, hogy saját léte kerül veszélybe.
De mi történik, ha hagyjuk, hogy a mesterséges intelligencia vegye át a vezetést és az kezdi el a tömegeket információkkal ellátni? Mi lesz a különbség? Nos, az eddigi bizonyítékok arra utalnak, hogy ez általánosságban rontja a web minőségét. A mesterséges intelligencia dicséretes képessége, hogy képes a szövegek újrakombinálására, de ehhez végső soron az emberek hozzák létre az alapul szolgáló adatokat. Ezek olyan újságírók, akik felveszik a telefont és ellenőrzik a tényeket, vagy olyan fórumozók, akik megbeszélik mi a probléma egy géppel, és elmesélik egymásnak hogyan javítottak meg valamit. Ezzel szemben a nyelvi modellek és chatbotok által előállított információk gyakran tévesek. A trükkös dolog az, hogy olyan módon tévesek, amit nehéz észrevenni.

Az MI szavakat generál, de ezek mögött
nincs igazi érték. Nem tesz említést fontos tényezőkről, gyakran rosszul értelmezi a tényeket, és a nagyobb internetes jelenlétet fontosabbnak gondolja. Nincs szakértelem az előállított információkban, mert csak találgat. A Stack Overflow modjai szerint a válaszok nem a valós világ tapasztalatai alapján állnak, viszont terjedelmesek, ezért időbe és szakértelembe kerül a kibogozásuk. Ha a gép által generált tartalom kiszorítja az emberi szerzőséget, akkor nehéz, sőt lehetetlen a károkat teljes mértékben feltérképezni. És igen, az emberek is bőséges forrásai a félretájékoztatásnak, de ha a mesterséges intelligencia rendszerek azokat a platformokat is elnyomják, ahol az emberi szakértelem jelenleg virágzik, akkor kevesebb lehetőség lesz a hibák orvoslására.
A mesterséges intelligencia webre gyakorolt hatásait nem egyszerű összefoglalni, mert abban sokféle mechanizmus játszik szerepet. Egyes esetekben úgy tűnik, hogy a mesterséges intelligencia vélt fenyegetését arra használják, hogy igazolják a más okokból kívánt változtatásokat (mint a Reddit esetében), míg más esetekben a mesterséges intelligencia fegyver a cégek és a tartalmakat létrehozó emberek közötti küzdelemben (Stack Overflow).
A mesterséges intelligencia skálázhatósága, a nyers bőség egyszerű ténye mindent megváltoztat. A világháló legsikeresebb oldalai közül sok a méretarányokat fordítja előnyére, akár a társadalmi kapcsolatok vagy a termékválaszték megsokszorozásával, akár az internetet alkotó hatalmas információhalmaz rendezésével. Ez a méretarány azonban emberek tömegére támaszkodik a mögöttes érték létrehozásában, és az emberek nem tudják legyőzni a mesterséges intelligenciát, ha tömegtermelésről van szó. Több évtizedes kutatások bizonyítják, hogy a mesterséges intelligencia rendszerek fejlesztésének legjobb módja nem az, ha megpróbáljuk megtervezni az intelligenciát, hanem jobb, ha egyszerűen több számítógépes teljesítményt és adatot allokálunk a probléma megoldására. A gépi skála legyőzi az emberi kurátori munkát, és ugyanez igaz lehet a webre is.
De vajon feltétlenül rossz dolog, ha a mesterséges bőség miatt megváltozik az általunk ismert web? Egyesek azt mondják, hogy ez a világ rendje, és megjegyzik, hogy maga a web ölte meg az előtte lévő világot, és gyakran a jobbik irányba. A nyomtatott enciklopédiák például szinte teljesen kihaltak, a Wikipedia kezelhető terjedelme és hozzáférhetősége legyőzte az Encyclopedia Britannica súlyát és tekintélyét. És a mesterséges intelligencia által generált tartalmakkal kapcsolatos összes probléma ellenére is rengeteg lehetőség van a javítására, például a hangsúlyosabb forrásmegjelöléstől kezdve a nagyobb emberi felügyeletig. Ráadásul, még ha a webet el is árasztja a mesterséges intelligencia szemét, ez hasznosnak is bizonyulhat, mert ösztönözni fogja a jobban finanszírozott platformok fejlesztését. Ha például a Google következetesen szemetet ad ki a keresőjében, akkor lehet, hogy hajlamosabbak leszünk fizetni a megbízható forrásokért, és közvetlenül azokat meglátogatni.
A mesterséges intelligencia által jelenleg okozott változások csak a legújabbak a web hosszú történetében. Lényegében az információért folyó harcról van szó, arról, hogy ki készíti, hogyan férhet hozzá, és ki kap érte pénzt. De hiába ismerős a harc, arra semmi garancia nincs, hogy a következő rendszer jobb lesz, mint a mostani. A jelenlegi döntéseink fogják meghatározni, hogyan fog fejlődni.